Since the dawn of time if you needed a reliable way to synchronize data within or between systems one of the best answers to that problem was rsync. It’s been in continuous development since 1996 and by now has code quality and feature set that is basically unrivaled. But what it never got was any sort of parallel transfer option. You could pipe it up with xargs and hack your own, but even that could cause problems as folders may not have yet been created when another sync thread comes along. So if you had the time to just wait for it to move a single file one at a time you were fine. It would, no doubt about it, sync your data even over an unreliable WAN connection. But like all things TCP latency and packetloss cause massive backoffs (true for cubic, reno, etc) and your transfer rate is going to crawl.
So how do we move large datasets with reliability AND speed? Let’s do some testing and find out.
Dataset: My personal repo of Ubuntu ISO files going back to 12.04. It clocks in at 193GB.
Environment: LAN 10Gbit NVME to NVME
Contender #1: rsync
As a baseline, rsync finishes in 10 minutes 34 seconds.
Contender #2: rsync + HPN-SSH
HPN is a set of patches for SSH and SFTP that tune the software stack for TCP performance. It also allows you to forgo encryption, which will be the limiting factor for large pipe local networks. Over longer runs (WAN) TCP bandwidth delay product is likely to be your bottleneck. And HPN is specifically made to address this. Result: 9 minutes 8 seconds. It’s faster but it won’t blow you away. About as expected as HPN is more tuned for solving TCP performance problems that aren’t going to be an issue on LAN.
Contender #3: rsync (again!) daemon
Did you know that rsync has another mode that bypasses SFTP? Many people who have used it for years don’t know of it. You must configure each storage location you want to be available in /etc/rsyncd.conf. See an example:
uid = nobody
gid = nobody
address = 10.10.100.55
use chroot = yes
max connections = 10
syslog facility = daemon
pid file = /var/run/rsyncd.pid
log file = /var/log/rsyncd.log
lock file = /var/run/rsyncd.lock
[file]
comment = rsync
path = /rsync/
read only = no
dont compress = *.gz *.bz2 *.zip
auth users = linuxuser1
Once that is done you can hit it from a remote machine. The daemon mode has no encryption, so it’s only to be used on trusted networks. LAN or over VPN. Local firewalling would be a good idea. Default port is TCP/873. Results? 4 minutes 1 second.
Contender #4: rclone
A newer piece of software, rclone is designed to provide remote storage access for a wide array of storage types. Check out the whole list. It can get you access to perform operations against Google Drive, WebDAV, Dropbox, or even object store systems like S3. But for today we are interested in a fancy trick it can do. Something rsync never learned. Parallel operation. It’s switch configurable, but the default of 4 was fine for testing. Same dataset over rclone was done in 5 minutes 43 seconds. While I didn’t get 4x speed over rsync like Jeff Geerling, it put up a good result.
Contender #5: fdt
Let’s get a bit more exotic. FDT is a java jar that you can use to move files over any network that can handle TCP. It autoscales threads, buffers, and streams to find out the limit of the pipe and peg it out. And performance was impressive. The only tool today that maxed out the link speed and was very flat at line rate for the whole test. Done in 2 minutes 33 seconds, it was by far the fastest. But there are drawbacks. FDT does not do directory structure. It can do individual files or you can give it a pre-compiled text list of files to operate on. Since it won’t look into folders, I had to use truncate to make a sparse file of the same size as my dataset to test against.
truncate -s 193G testfile.img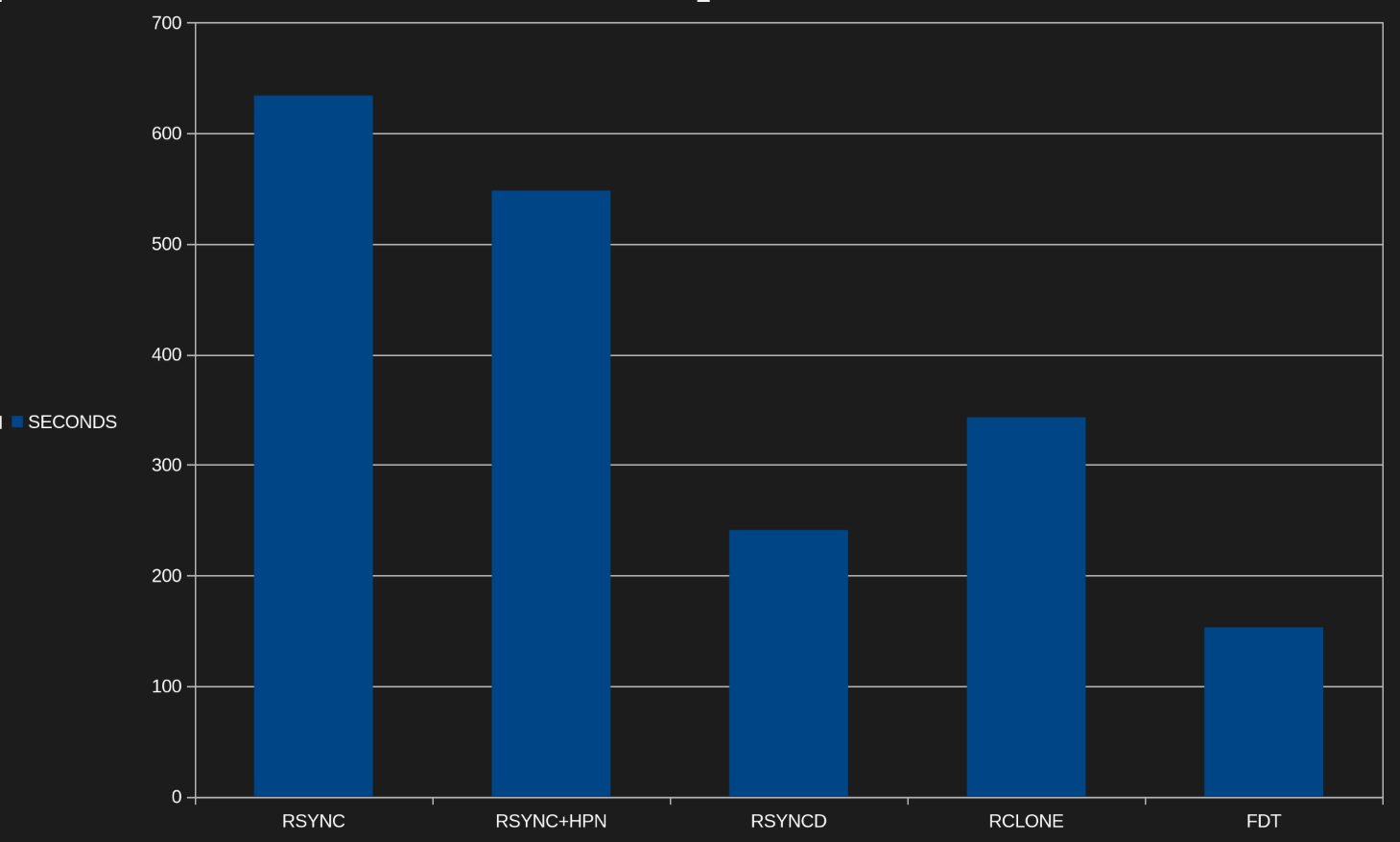
So what did we learn? There are tradeoffs like all things in life. Here they are speed, security, or convenience. It’s all a toolbox, so reach in and use your brain to get building.