Linux, as beautiful as it is, does have some longstanding problems with resource scheduling. Over the years various attempts to resolve the issue have been hampered due to the nature of the problem. Different applications need different performance tuning parameters. People that deploy only a single application on a server don’t care about desktop responsiveness. And desktop users don’t care as much about a server use case that requires maximum throughput at all cost. So you now have an operating system that is used by millions of people on millions of different types of hardware in millions of different ways. You can’t tune a generic profile that would work for everyone.
Graceful handling of storage IO tasks is the job of the scheduler. There are several. Noop, BFQ, CFQ, deadline. They all have different algorithms and design specifications. And it would be understandable if that was the first place you looked when you notice your Linux desktop becoming unresponsive under heavy disk IO load. While some schedulers are better than others at maintaining responsiveness, BFQ probably being the best fit for this type of use, a larger problem lies elsewhere.
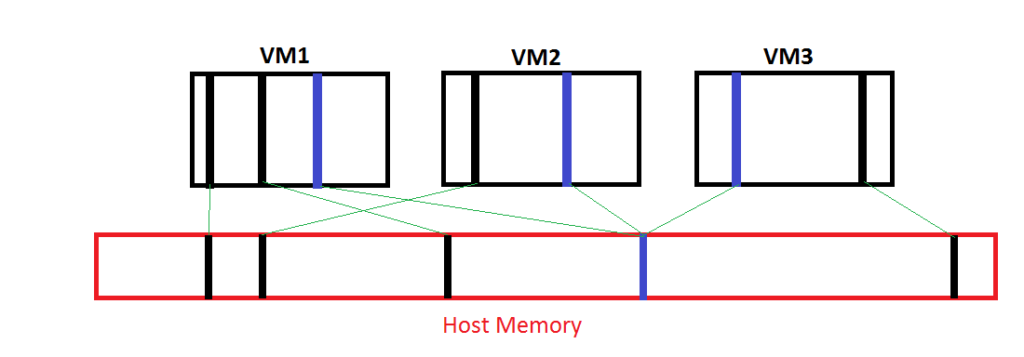
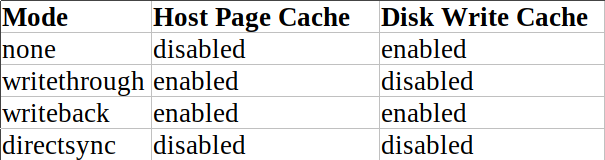
Linux famously caches storage operations in RAM to improve performance when not under memory pressure. Because, why not? It’s basically free. The problem with caching storage operations between volatile memory and non-volatile storage is the possibility for data loss. Writes in flight will be lost if there is a power disruption, for example. So this can create problems that the conservative Kernel and distro maintainers understandably try to tune around. By default the Kernel is allowed a small amount of cache to hold asynchronously before it is forced to stop everything and call a synchronous write to flush its data to NV storage. We have some parameters:
vm.dirty_background_ratio
The percentage of data that is allowed to be in memory and uncommitted to disk. The possibility for data loss exists in this state, hence the name “dirty.” This is set at 10% by default. For many more desktop oriented workloads this is going to be quite low.
vm.dirty_ratio
The dirty ratio sysctl setting is the max the Kernel will keep before halting everything and forcing a synchronous write. If you feel your desktop ‘hitching’ for a period of time during IO load, you may very well be seeing this exact issue playing out. The storage system can’t keep up, throws up its hands, and forces everything to stop so it can catch up. The default 20% here is, again, quite low for what most would want on a desktop.
vm.dirty_expire_centisecs
Essentially a timer, the expire parameter states how long dirty data can sit waiting to be flushed async before the kernel forces a sync call. The value is in centiseconds, so divide by 100 to get normal seconds.
If your data isn’t particularly mission critial you can increase each of these values in order to allow the system to work through IO spikes asynchronously. This will lead to a much smoother experience for other applications.